XBIS Encoding Format |
|
XBIS Encoding Format |
|
|
The XBIS encoding format mirrors the standard text form of an XML document in that all components of the document are present in the same order they'd appear in text. What differs is that XBIS uses a more compact representation of the components, and presents them in a more easily processed form. The compactness comes mainly from taking advantage of the highly repetitive structure of a normal XML document, where the same element and attribute names are typically used many times over. XBIS defines each name as text only once, then uses a handle value to refer back to the name when it is repeated. This same approach is used with namespaces, so that even namespace prefixes are not repeated as text. XBIS can also apply this approach to attribute values and character data, which often use the same text repeatedly. The extent to which this is done is an encoding option, but does not actually effect the format itself; a reader does not need to know what options were used to generate the encoding in order to build a document representation from the encoded form. This is an important concern for general usage, since it allows documents to be exchanged between XBIS users without the need for any external information (such as a schema, or parameter settings). Besides the more compact representation, XBIS gains speed on the input side by presenting the document data in predigested form. This eliminates the need for any complex parsing of the input and allows the document to be reconstructed with minimal overhead. Building BlocksThe XBIS encoding builds up from several simple types. These simple types are described in this section.
Integer ValuesPositive integer values are used extensively in the encoding. The standard format of representing these values uses the low-order 7 bits of a byte for the actual value representation, with the high-order 8th bit used as a continuation flag - when the 8th bit is set, the next byte in the encoded stream contains another 7 bits of the value. Figure 1 shows how this looks when applied to values of various sizes. Values in the range of 0-127 can be represented in a single byte, as shown in the top image. Values of 128-16383 require two bytes, as shown in the second image (where the upper byte comes first in the encoded form). Larger values require more bytes, all the way to a maximum of five bytes to represent the maximum possible integer value. In actual use, the values being encoded can generally be represented in one or two bytes. Quick ValuesQuick values are a way of representing a limited range of positive
integer values within a portion of a byte. This format is often used
in combination with flags in a byte. When a value is to be encoded in
this manner it is first incremented. If the incremented value fits
within the portion of the byte allowed for the quick value, the value
is stored directly within the byte. Otherwise, a StringsStrings are the basic building blocks of the serial form. The
general string format uses a leading length value which gives the
number of characters (not bytes) in the string, plus one. The
value This length value is encoded as a normal integer value, as described above. It is followed immediately by the actual characters of the string. Each 16-bit Java character is also encoded as an integer value, so the length of the string data in bytes can potentially be up to three times the number of characters in the string (but for characters in the standard ASCII range the length in bytes will be the same as the number of characters). String lengths can also be encoded as quick values in some cases.
These work slightly differently in that the actual character length
of the string is encoded as a quick value, rather than the
length-plus-one value used in the general format. Since there is no
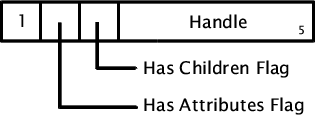
way of representing a HandlesHandle values are used to refer to previously defined items, which include element and attribute names, namespaces (both active and defined), namespace URIs, and optionally attribute value and character data strings. Each type of item listed uses a separate set of handles in order to keep the handle values as small as possible, giving the most efficient encoding. The context of a handle reference always determines which type of handle is being referenced. Actual values start at A When handles are encoded in quick value fields the actual value
stored is one greater than the handle value, since as described above
the quick value format makes special use of the Names and NamespacesElement and attribute name definitions use a common format. The first byte of the definition, shown in Figure 2, contains a quick value field for an active namespace handle, along with a separate quick value field for the local name length.
If the active namespace handle value is larger than can be represented in the quick
value field (indicated by a If the namespace used for a name has not previously been defined it may be
included in the name definition. This uses the handle value
Going back to the basic name definition, the additional information for the local name is encoded after any additional information for the namespace. If the name length quick value field in the name definition byte is too small to hold the length, the full length follows any namespace information. It is followed by the encoded characters of the local name. Structure EncodingXBIS is a stream encoding which is mainly intended for use with single documents. However, the format allows for encoding arbitrary combinations of elements and documents, and there are cases where this may be very useful to an application. Consider the case where multiple documents of the same type are being transferred from one program to another, for instance. The first document encoded would define most or all of the element and attribute names used in the entire series of documents, allowing the names to be referenced as simple handles in all the following encoded documents. Each XBIS stream starts with four bytes reserved for XBIS itself.
The first byte is a format identifier, which is set by the encoder to
specify the format version used to encode the document and checked by
the decoder to ensure that it is able to process that format. The
only value used at present is The second byte is an identifier for the adapter used to drive the
encoding. This value is set by the encoder for information purposes
only; the decoder reads this value and makes it available to the
application but may not otherwise use it. This requirement is
intended to preserve compatibility between all XBIS adapters. There
are currently three values defined for this byte, The remaining two bytes of XBIS header are reserved for future
use. They are currently written as After the header the stream consists of one or more nodes. These are the primary document structure components, representing everything from a complete document down to a comment or character data string. Attributes are not considered nodes in the XBIS encoding, though, and are handled separately. At the top level only two types of nodes are valid, element nodes and document nodes (when XBIS is used for complete documents, only the document nodes are valid at the top level). Each of these may in turn contain other nodes (including element nodes) as content. The content node definitions are nested within the definition of the containing node. Each node begins with a node definition byte, which may be followed by additional information for the node. This node definition byte uses different formats for different types of nodes, with the high-order bits used as flags to identify the format. Element NodesElement nodes use the format shown in Figure 4. The high-order bit of the node definition byte is always a 1 for an element node, and the next two bits are used as flags for whether the element has, respectively, attributes (including namespace declarations) and content (0 if not, 1 if so). The remaining bits are a quick value for the element name handle, extended if necessary into the following byte(s). If the name has not previously been defined, the new name definition immediately follows the node definition byte.
If the element has attributes, these are next. Attributes begin with an attribute definition byte, taking one of the forms shown in Figure 5. The top format is used for attributes with ordinary (unshared) values. The bottom format is used for attributes with shared values, which use handles to avoid encoding the same text repeatedly. Both ordinary and shared attribute values may be used in any combination.
Both attribute definition byte formats use the low-order bits of the byte for a quick value of the attribute name handle (extended, if necessary, to the following byte(s)). If the name has not previously been defined the name definition immediately follows the attribute definition byte. The actual value of the attribute is next. For ordinary values, and for new shared values (as indicated by the flag in the attribute definition byte), these are strings in the general format. For previously-defined shared values the value is represented by a handle which identifies the value text. The list of attributes for an element is terminated by a If the element has content, the content nodes are next. The
content nodes can be of any type (subject to XML structure concerns -
a document as content of an element is obviously invalid, for
instance). Each begins with a node definition byte, and as with the
attributes the list of content nodes is terminated by a
Text NodesPlain text (ordinary character data) nodes use the format shown in Figure 6. This gives the text length as a quick value in the low-order bits of the node definition byte (extended, if necessary, to the following byte(s)). It is followed by the actual encoded characters of text.
Shared text nodes use the format shown in Figure 7. This gives the handle for shared text in the low-order bits of the node definition byte (extended, if necessary, to the following byte(s)). If the text has not previously been defined (as indicated by a 0 value for the handle), the text definition immediately follows the node definition byte, as a string in the general format. Both types of text nodes can be used within a single document, in any combination. Namespace Declaration NodesNamespace declaration nodes can be used both to define new namespaces and
to reference previously-defined namespaces. The first byte uses the format
show in Figure 8, with a quick value field for a namespace definition handle
in the low-order bits. If the node is redeclaring a previously-defined
namespace the handle value will reference that namespace definition. As usual,
a handle value of
Namespace declarations always apply in the scope of an element. When a namespace declaration node is used it must precede the element it applies to. Namespaces may also be declared as part of an element or attribute name definition, when the namespace applies to that name. When a namespace is first defined it's assigned a namespace definition handle, and each time it's declared it's assigned an active namespace handle. The active namespace handle is only valid within the scope of the element declaring the namespace, while the namespace definition handle is valid from the point of definition on. Each namespace definition associates a particular prefix (which may be the empty prefix) with a particular namespace URI. If multiple prefixes are defined for the same namespace URI a separate namespace definition is included in the serial form for each prefix. The actual URI will only be encoded with the first namespace definition, though, and will be referenced using a handle in any other
Other NodesThe other node types use a simple format in which the node definition byte just identifies the type of node, and any additional information for that node type is in the following bytes (with text items using the general text format, as described under Strings, above). These other node types are:
The value Note that most of these node types are not required for preserving the canonical form of XML documents, since XML Canonicalization discards Document Type, Notation, Unparsed/Skipped/External Entity, and Element/Attribute declaration information. These types are supported by XBIS to allow its use as a serialization mechanism for XML document models, but they should be considered optional. |